Character Encoding: A Quick Primer

Introduction to Character Encoding
Understanding how Character Encoding works is an essential part of understanding digital evidence. It is part of the common core of skills and knowledge.
A character set is a collection of letters and symbols used in a writing system. For example, the ASCII character set covers letters and symbols for English text, ISO-8859-6 covers letters and symbols needed for many languages based on the Arabic script, and the Unicode character set contains characters for most of the living languages and scripts in the world.
Characters in a character set are stored as one or more bytes. Each byte or sequence of bytes represents a given character. A character encoding is the key that maps a particular byte or sequence of bytes to particular characters that the font renders as text.
There are many different character encodings. If the wrong encoding is applied to a sequence of bytes, the result will be unintelligible text.
ASCII
The American Standard Code for Information Interchange, or ASCII code, was created in 1963 by the American Standards Association Committee. This code was developed from the reorder and expansion of a set of symbols and characters already used in telegraphy at that time by the Bell Company.
At first, it only included capital letters and numbers, however, in 1967 lowercase letters and some control characters were added forming what is known as US-ASCII. This encoding used the characters 0 through to 127.
7-bit ASCII is sufficient for encoding characters, number and punctuation used in English, but is insufficient for other languages.
Extended ASCII
Extended ASCII uses the full 8-bit character encoding and adds a further 128 characters for non-English characters and symbols.
Unicode
Fundamentally, computers just deal with numbers. They store letters and other characters by assigning a number for each one. Before Unicode was invented, there were hundreds of different encoding systems for assigning these numbers. No single encoding could contain enough characters: for example, Europe alone requires several different encodings to cover all its languages. Even for a single language like English no single encoding was adequate for all the letters, punctuation, and technical symbols in common use.
These encoding systems also conflict with one another. That is, two encodings can use the same number for two different characters, or use different numbers for the same character. Any given computer (especially servers) needs to support many different encodings; yet whenever data is passed between different encodings or platforms, that data always runs the risk of corruption. Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language.
The Unicode Standard is a character coding system designed to support the worldwide interchange, processing, and display of the written texts of the diverse languages and technical disciplines of the modern world. In addition, it supports classical and historical texts of many written languages. Unicode 10.0 adds 8,518 characters, for a total of 136,690 characters.
Unicode can be implemented by different character encodings; the Unicode standard defines UTF-8, UTF-16, and UTF-32 (Unicode Transformation Format).
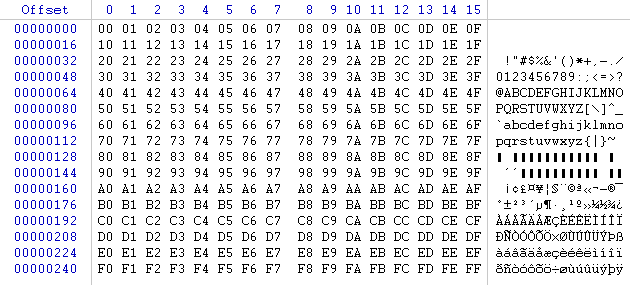
Codepoint
The number assigned to a character is called a codepoint. An encoding defines how many codepoints there are, and which abstract letters they represent e.g. “Latin Capital Letter A”. Furthermore, an encoding defines how the codepoint can be represented as one or more bytes.
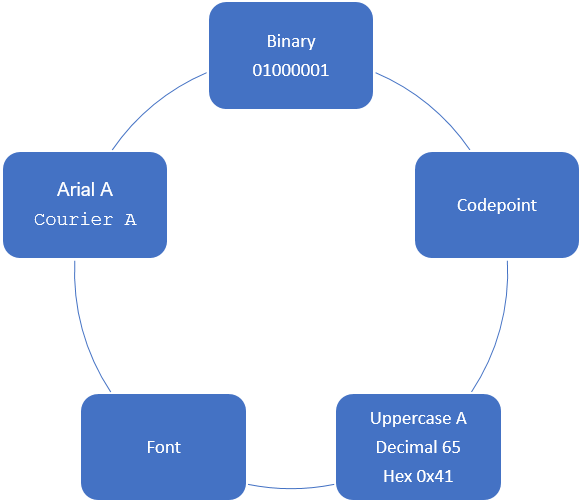
The following image shows the encoding of an uppercase letter A using standard ASCII.
UTF-8, UTF-16 and UTF-32
UTF-8 is the most widely used encoding and is variable in length. It is capable of encoding all valid Unicode code points and can use between 1 and 4 bytes for each code point. The first 128 code points require 1 byte and match ASCII.
UTF-16 is also a variable-length and is capable of encoding all valid Unicode code points. Characters are encoded with one or two 16-bit code units. UTF-16 was developed from an earlier fixed-width 16-bit encoding known as UCS-2 (for 2-byte Universal Character Set).
UTF-32 is a fixed length encoding that requires 4 bytes for every Unicode code point.
Browser Data Analysis
It is important to understand character encoding when examining Internet and browser data. Browser applications use a variety of different encoding methods for storing data. For example, some browsers use UTF-16 for storing page titles and the default Windows encoding for storing URL data (e.g. Windows 1252). Windows 1252 is a 1-byte character encoding of the Latin alphabet, used by default in the legacy components of Microsoft Windows in English and some other Western languages.
Selecting a Code Page in NetAnalysis®
An appropriate Code Page can be selected when creating a New Case in NetAnalysis®.
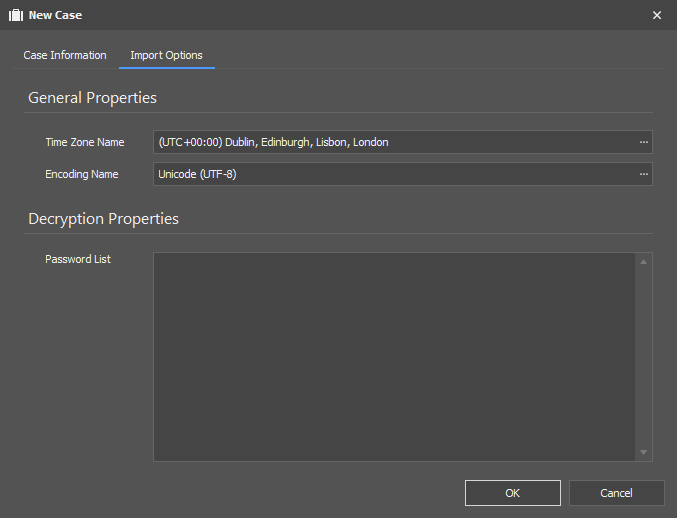
Clicking the button next to the code page shows the following window. This allows the user to select the appropriate code page (if required).